张瑾:人工智能与商业变革


什么是人工智能
上个世纪90年代,IBM开发的象棋电脑“深蓝”,在国际象棋的平台上战胜了当时的世界冠军卡斯帕洛夫,在当时引发了不小的轰动。人类第一次意识到人工智能以机器这样一个算力形式是可以在棋类游戏的任务上面超过人类,完成人所不能完成的任务的。
上世纪40年代,人类发明了现代意义上的第一台晶体管计算机,简单来说,就是一个存算机,告诉人类如何去存数据、算数据。这个伟大发明的核心功能就是计算。可以说人工智能是我们发明的最伟大的计算工具,一个高阶的算盘。
在那之后十年左右的时间,人类有了一个更伟大的想法——能否依靠这个伟大发明的计算能力来逼近人类的所有能力。这就是人工智能最早期的想法的提出。从那之后,在很多任务上面就出现了通过计算来逼近人的情况。在这个想法提出之后,自然诞生出下一个问题点,人类有很多的能力和功能,在哪个任务上做到通过纯粹的计算来逼近人,就可以做到最基础的、最具颠覆性的,能够把所有的任务都完成?这一时期,人类计算科学历史上最伟大的科学家之一——图灵,他认为在众多的任务当中有一个任务是最基础而重要的,这个任务叫对话,在对话这个任务上面,通过纯粹的计算能够逼近人。就可以实现人工智能,图灵在之后就提出了图灵测试.。
什么是图灵测试?简单来说就是在对话这个任务上面,通过纯粹的计算去逼近人。在一个互相看不到对方的空间里,中间隔着一堵墙。墙的一侧是人类判官,他在跟墙后面不知道是人还是一个计算设备进行对话。在通过多次对话之后,他已经无法确认现在正在跟人交流还是在跟一个计算设备交流的时候,就可以认为在对话这个任务上面,纯粹的计算就可以逼近人了。今天的大语言模型的突破。为什么叫CHAT,为什么把GPT称之为CHAT GPT,其实有很大一部分原因,是当年图灵所指出来的在对话这个任务上面做到突破,通过持续的计算来逼近人是可以实现最基础的人工智能的。
怎样实现人工智能?
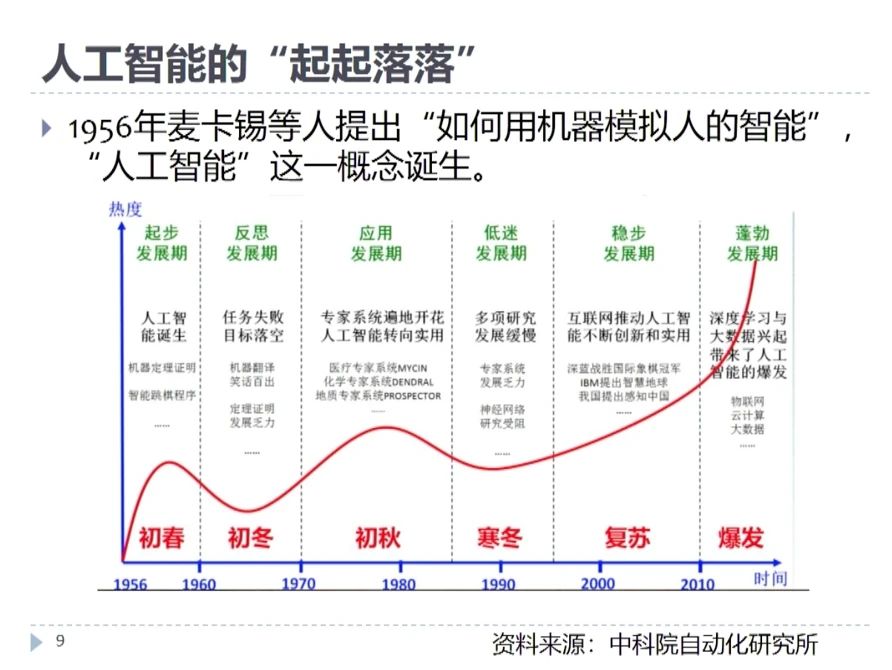
人工智能的发展历史出现了三次重要的起伏,波峰和波谷。从上世纪五十年代开始。人工智能的发展历史是呈现先起后落,再起再落,到今天一路向上的发展态势。为什么会出现这样的趋势呢?因为人类一直在探究哪一种计算算法能够最有效的逼近人,科学家找了很多方法,然而这些方法在发展历史当中被认为短期有效,长期又遇到了瓶颈。人工智能发展到今天,人类发现了有一种计算方法,它在通过纯粹的计算来逼近人的过程当中目前被认为是最有效的,我们称之为神经网络。
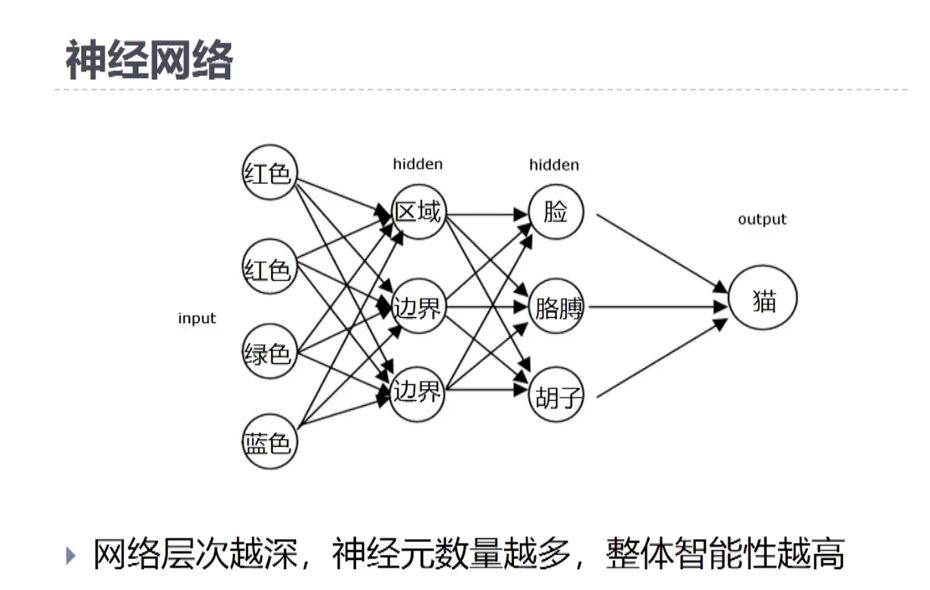
神经网络算法对于算力、数据的消耗很大,当今算力、数据极大丰富。神经网络算法的优势得到了极大的体现。神经网络算法用各种各样小的计算单元,拼成一个网络状的形式,来实现更大的智能体的功能和计算更复杂的任务。这个想法是受到人类大脑的结构启发,大脑是由很多简单的神经元细胞组成,这些神经元细胞每一个都不能独立完成复杂的生物运算能力,只能做一些简单的脑电的处理,但是就是这样的一些简单的神经元细胞,经过复杂的网络拼接,把成千上万的细胞拼在一起之后,我们的生物体大脑开始可以完成一些复杂的任务。比如怎样通过大脑细胞的传递来完成对一个猫的概念的提取和认知。如果一张图片当中有一只小猫,我们的大脑很容易识别得到这里面有一只猫,猫的概念很清楚的浮现在纸面上。但是大脑是怎么处理的呢?就是靠一些简单的小的神经元细胞一步一步地叠加上来。比如我们看到的红色、红色、绿色、蓝色,代表非常简单的视神经元细胞。它会捕捉到一些像素信息,这些像素信息再向上传递,变成左面红色,右面蓝色,中间就会有区域的概念,区域的概念传到上一级之后,发现有一些器官的概念了,有猫的脸,猫的胡子,这些器官再向上传递就会形成猫的整体这样一个认知,这是我们对于大脑的理解,我们以为大脑是这么处理信息的。那我们去做一个类比,把这里面每一个圆圈所代表的神经元细胞换成计算单元当中最简单的计算细胞。那它只能算1+1=2甚至是2x3=6这么简单的运算,但是这么简单运算,通过多次的拼接,我们是可以期待它完成更复杂计算任务的,这就是神经元网络的方法的一个最基础的假设和设计,我们期待的是这个网络随着层数增多、神经元细胞计算单元的增多,让它整体呈现出越来越复杂的计算能力和计算特征。
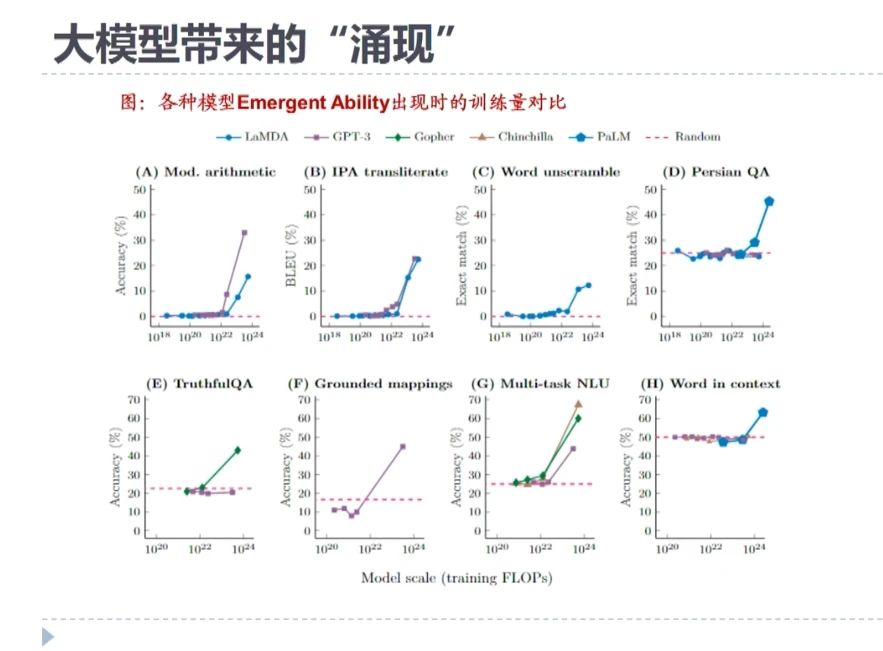
不出所料,这个网络当中的神经元细胞数量、计算单元的数量慢慢增多的时候,它所表现的智能性是比较高的,而这个问题也在这个方面上呈现了一个拐点。当把神经元网络细胞的计算单元数量从几千个,慢慢扩展到几万个,再到千万亿,十亿百亿,它会呈现这样的一个趋势,当神经元的计算单元数量突破千亿的时候,它应该是在如图所示的这样一个预测位置,这次大模型的出现,就是在这个位置上出现了拐点。当神经元网络的细胞数量到1750亿的时候,它整体呈现的智能性不是线性的变化,而是跳跃性的发展,我们就可以认为它实际上呈现出一种现象叫“涌现”,这是2023年非常热的一个词汇。
那到底什么是“涌现”?我们以为整个网络的发展趋势是一个纯线性的变化,但是在这个实测点上出现了一个巨大的跳跃。这个巨大跳跃就带来了大模型的变化。这里面每一张图呈现的都是一个“涌现”。也就是当神经元数量突破一定规模的时候,它整体的智能性都会呈现这样的跳跃。所以这八张图在最后一个位置上突然跳起来了,那之后所带来的“涌现”,就是我们意想不到的智能性,也就是大语言模型给我们带来的变化。
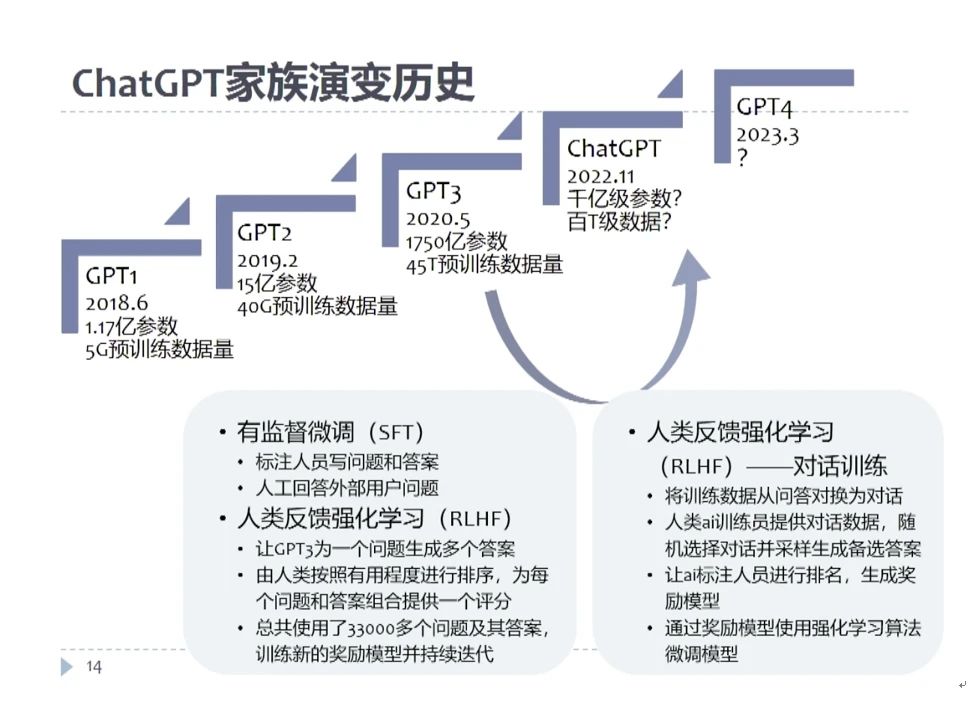
在这里把整个发展历史做一个总结,以OpenAI的产品ChatGPT为例,其实这个产品早期是没有得到整个学界和业界认可的,在GPT1的时候,也就是2018年6月份,这个模型的参数是1.17亿。模型参数虽然已经足够大了,但是它所呈现的智能性还是非常的弱小,所以2019年2月份推出GPT2的时候,我们依然没有对它的工作给予足够多的重视。首次进入人类视野范围内就是2020年五月份,一家公司首次将模型参数推到1750亿,我们突然发现它所带来的不是顺序的线性的变化,而是跳跃的突变。2022年11月30号, OpenAI推出ChatGPT,那天我们从产品的角度了解到了这个新生事物,语言模型是可以做到很多以前完成不了的任务的。
回归商业视角,人工智能的突破将会给人类带来那些改变?
回到商业的本质下,科技的突破最终要考虑对于人的改变。从商业视角来看,大语言模型或者说是AI的突破给商业带来了什么样的变化?其实变化是很多的,从技术本身来说,要考虑它的算力,算法,计算所需的数据,所以这样的一个模型出现之后,一定会消耗很多的计算数据,消耗很多的算力,自然也会出现大家一直在讨论的芯片问题,例如英伟达推出的高端计算芯片——GPU。大语言模型的训练主要消耗的就是GPU的算力。这是我们在算法,算力和数据方面一定要去做的布局和思考。
在应用层面上,简单的以问题的形式抛出来,大家一块思考。比如说ChatGPT,它是以大语言模型为代表的生成式AI,这种模型出现其实是压缩和改变了整个知识供给的链条,或者说它将知识供给变成了普惠化的形式,我们换一个角度来理解,比如说原来很多问题我们需要通过一些专业的咨询机构和知识机构才能够获得解决办法,但是今天生成式AI的重大突破让这些问题可以通过大语言模型来慢慢实现。大语言模型带来的不只是技术突破,它微妙地改变了知识供给的逻辑,普惠化和压缩了整个知识供给的链条。那在这个链条上,原来很多的商业模式在大语言模型出现之后都会受到挑战。还有一点,数据经过一定成本的加工会变成信息,信息经过一定成本的加工会变成知识,那这个链条下自然会出现一个基于数据的服务,是不等于基于信息的服务,是不等于基于知识的服务的,因为数据变成信息是要投入很多成本的,信息变成知识要投入很多成本,互联网上主要的形态基本都是基于信息的服务形态。但是当大语言模型出现之后,知识从信息变成知识链条不需要投入太多的成本,甚至可能是用比较小的成本都可以实现,将信息转换为知识的时候,我们就可以做出这样一个推理,基于信息的服务是很容易转换而成基于知识的服务的。或者你可以认为他们之间化成等号了。换个角度来想,互联网上所有基于信息的服务是不是很容易就可以转成基于知识的服务?换句话说,当有人用基于知识的服务把线上所有的基于信息的服务再重做一遍的时候,这是一个商机还是一个未来的竞争机会?这是第一个角度。
第二角度,在大模型的时代,企业要不要去做大模型,2003年有篇文章叫《IT doesn't matter》,这篇文章当时很有名的一个观点——IT其实不重要。他把IT归结为像水、电、高速公路这样一个公共基础设施的定位和存在。这个观点是非常值得去考虑的。大模型出现之后,我们要重新定位它是公共基础设施一般的存在,还是企业要靠它来建立核心竞争能力?我们要考虑的是企业需不要建立自己在垂直领域当中的垂直模型,这个模型其实是回答了企业另外一个问题,我们讲说企业要成为平台型的企业。它有自己的生态,那这里面IT数字化的支点到底是什么形态。我们可以假想,以后的每一个产业每一个小的细分领域应该都会有一个垂直模型,而这个垂直模型不会太多,不会在每个领域当中都是百花齐放的。如果有一个模型做的比较好,它一定会汇聚整个行业上下游的数据和用户的关注。这个模型很有可能成为企业未来发展的一个平台的具象化表达,所谓的数字化平台更多呈现的是企业在这个行业当中先发建立自己的大模型,然后靠模型来整合整个行业的上下游数据,包括它的用户和市场。
另外,现在很多的商业模式、服务形态也要发生变化。举电商为例,原来电商是怎么服务的?消费服务的最典型代表是要做推荐,所以消费者登录到电商平台,它都会向你去做产品推送,给消费者更好的服务体验。在推送过程当中有一个默认的假设,即这里的AI能力都是单向的。什么叫单向AI能力?平台企业有AI能力,消费者、客户实际上是没有AI能力的,他们只是普通的人群,所以平台在做信息推荐、产品推送的时候,都是基于这样的一个假设。这个时候,它的AI能力的作用是怎样识别消费者最感兴趣的产品。但是当大语言模型逐步渗透进去之后,出现了这样一个趋势,不光是企业平台有AI能力,普通用户、消费者、市场上的每一个凡人,他都会有AI能力。当带有AI能力的用户到平台上购物,这就从单向AI变成了双向AI。这时,很多想问题的逻辑都会发生变化,比如刚才讲到的产品推荐。当用户有AI能力的时候。我们不是要给他推荐一个商品,而是要给他推荐成千上万个商品。
可能很多企业还要考虑一个问题,比如企业的内部组织架构也要做重新梳理。当模型慢慢进入到企业当中,会产生一个现象,举个例子,营销团队为了做一个项目,可能需要找财务团队来支持工作,所以现在会设立财务BP这样的岗位,但是有了大模型之后,营销团队通过大模型就可以捎带手的把财务的任务完成了,而且完成的效果会比专门的财务团队更好,这时候你发现组织之间的边界会被慢慢的打破和融合,那公司之间的边界也会出现很多变化,企业在“出海”过程当中要实现本土化,所以要雇佣当地的管理者和工人,也要派我们的高管过去,当有了大语言模型之后。我们是不是可以把模型派过去,而不需要把我们的人派过去?这些都是未来可能会发生的一些变化。
我们不是被AI颠覆,而是要成为懂AI的人
最后可能还要思考一点,就是人在这里面的变化,科技的进步最终是希望人能得到提升,大模型出现之后可能带给我们的很多管理者和用户的感觉都是更加的“卷”了,更加的有危机感。
不管大模型的突破多么迅猛,人还是核心,至少在今天这个时间点内,我们强调的是人机协同的概念。也就是说,人类不是被AI所颠覆,是被懂AI的人所颠覆。所以对于今天人的要求是尽早成为懂AI的那个人。懂得如何去跟AI进行协同,在企业的组织内、市场上去实现跟AI之间的协同,来完成之前别人完成不了和完成不好的任务。
总结
今天的AI发展是非常迅猛的,通过计算来逼近人的路线已经慢慢清晰。未来还会有更多更大的突破,但是不管突破有多么的迅猛,我们今天至少看到了一个方向,这个方向就是,人的核心竞争能力慢慢开始强调人机协同,我们要去懂AI,去利用AI。比如当你发现自己有能力将现在企业传统的管理变成一些生成式的逻辑的时候,你就可以优先借助大模型所带来的各种生成式的改变,当你不具备这个能力的时候,你会发现大模型的出现,你是无法借力的,甚至所考虑的只是大模型对人的颠覆,而没有去充分的利用。
我们要优先成为懂AI的那个人,不要担心被AI所颠覆,谢谢大家!
 微博
微博
 微信
微信
 视频号
视频号
相关文章:


